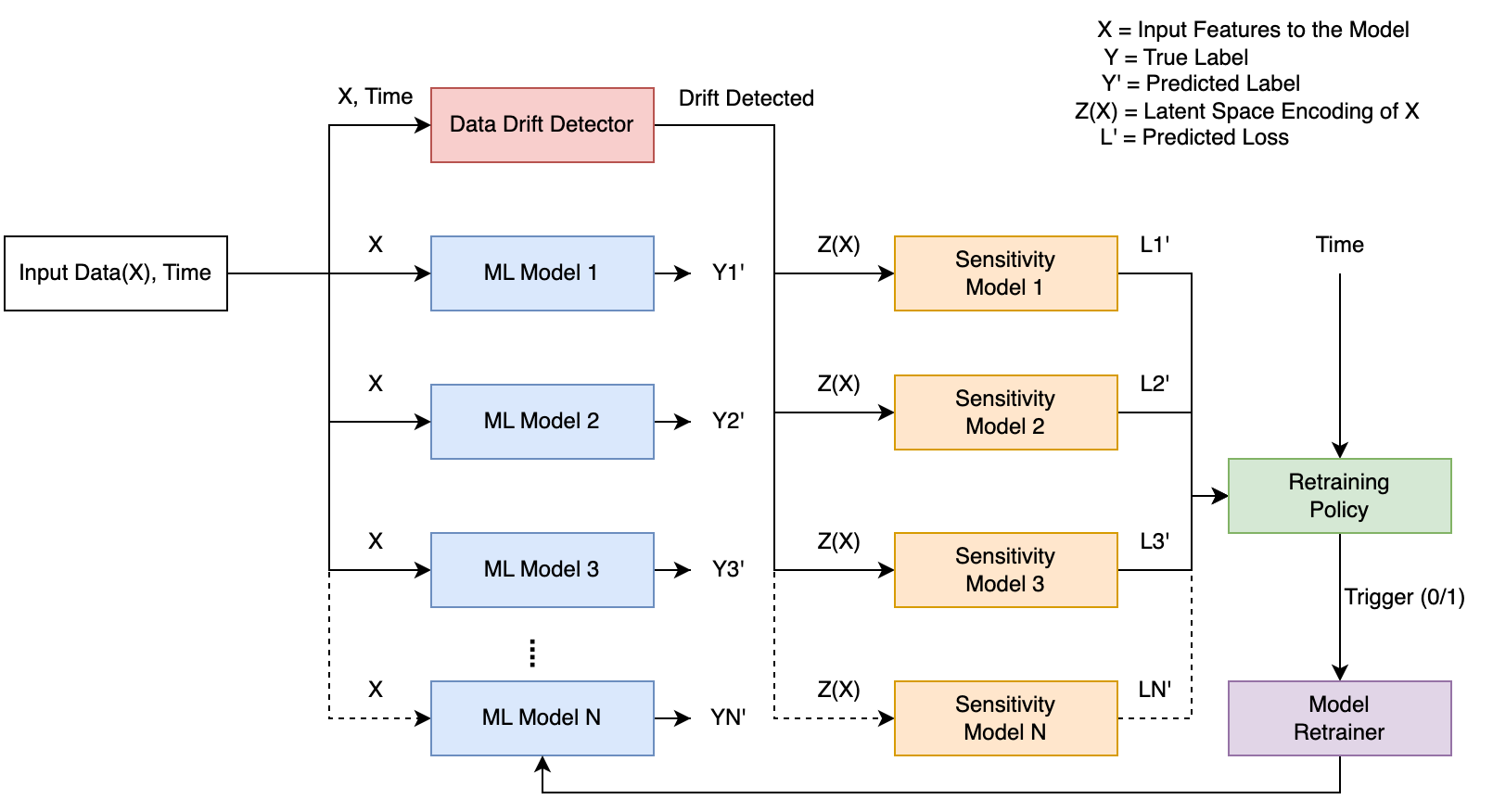
Overall system design of the proposed predictive model maintenance pipeline
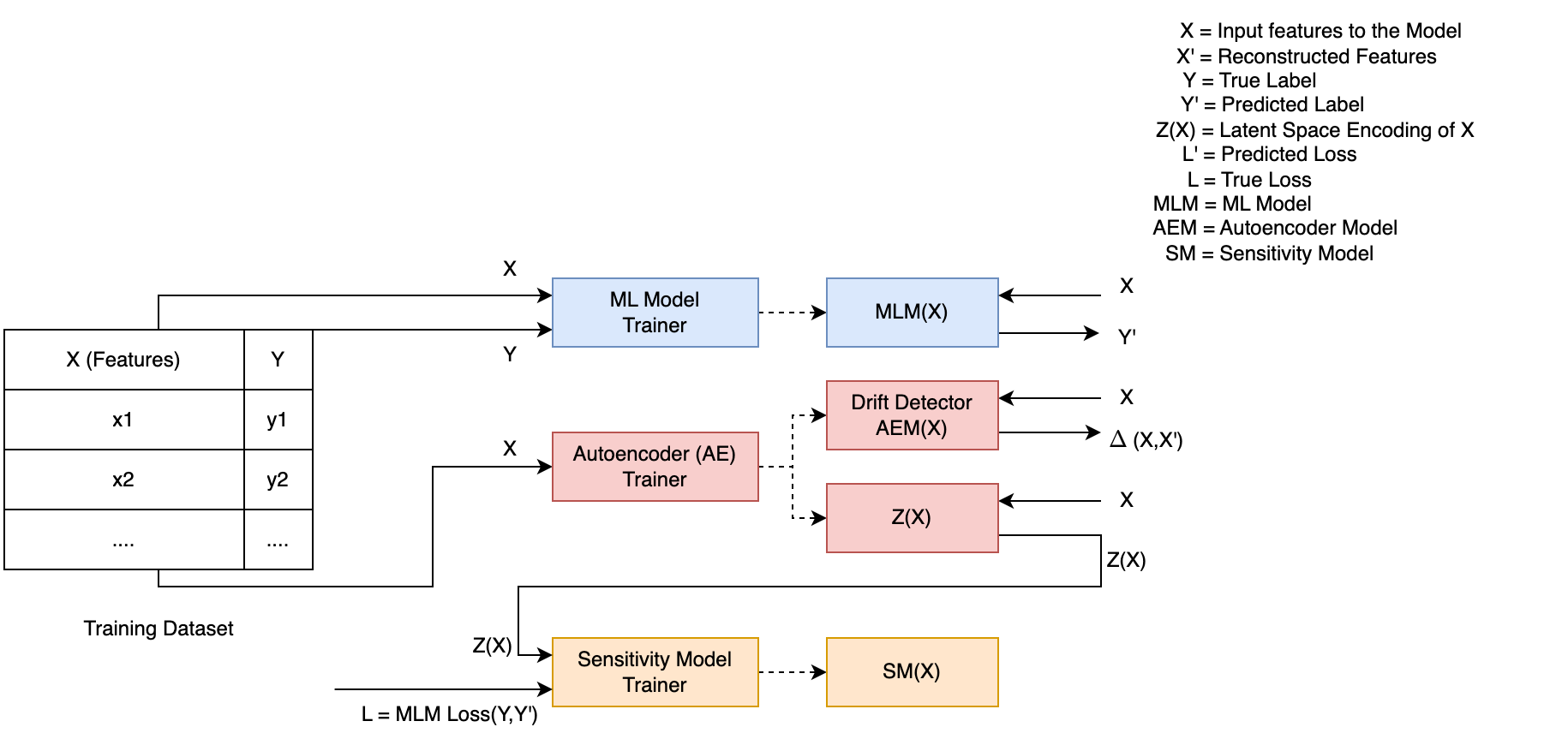
Describes how each of the components of the pipeline will be trained
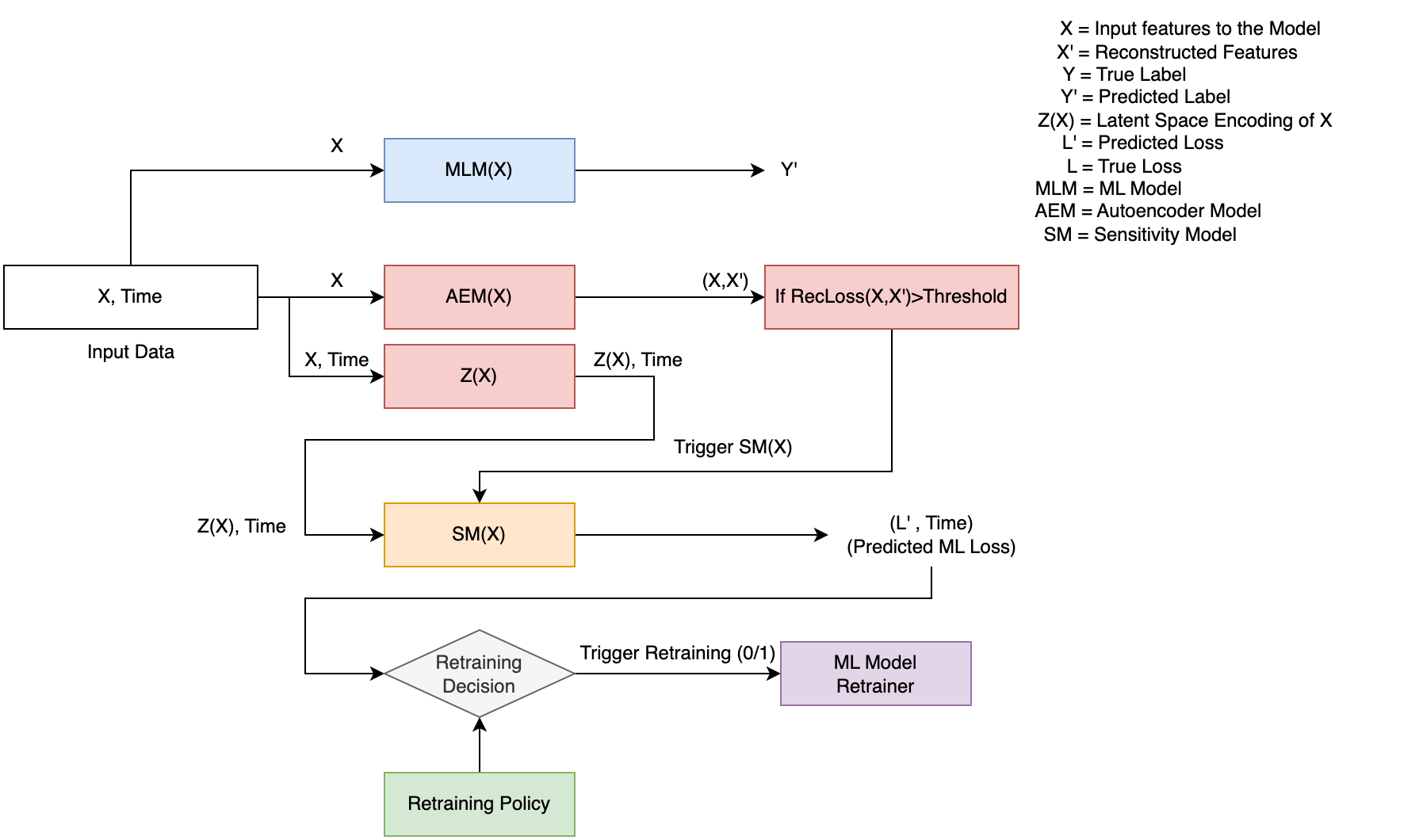
Machine learning (ML) models are used in a multitude of real world applications. These models are usually created assuming that the datasets they are trained upon are representative of the data they will encounter when deployed in production. A change in the underlying distribution of the features that an ML model relies upon can have disastrous consequences. These data distribution changes can be hard to spot and their impact on the quality of the resulting ML model predictions can be even harder to determine. Current model maintenance pipelines for dealing with this type of ``data drift’’ typically either wait until ML model errors are observed before taking action or retrain the model periodically according to some ad hoc schedule. The former approach can incur serious damage by the time errors are observed and corrective action is taken, and the latter approach can either waste resources if retraining is too frequent or incur damage if retraining is not frequent enough. Our current research aims at developing a model maintenance pipeline that is predictive, preemptively re-training models before excessive model losses occur while minimizing false alarms. The pipeline has multiple components: A drift detector that identifies when incoming feature vectors start straying away from the original feature distribution; a sensitivity model that predicts ML model losses for the drifted data points; a retraining policy that determines when to trigger the retraining of the ML model based on predicted future losses; and appropriate data synopses that can be used for rapid model retraining.